搜索引擎工作原理简单模拟
这里的模拟非常简单和傻瓜,但可以说明搜索引擎是如何处理页面的过程。
第一步:通过蜘蛛抓取页面;
什么是蜘蛛? 如何抓取页面?以文本形式下载,送会服务器。
第二步:网页文件处理
什么是蜘蛛? Googlebot、baiduspider、 Yahoo、Slurp、Msnbot 如何抓取页面? 以文本形式下载,送会服务器。 可能会做一些预处理,比如:压缩等 可能妨碍蜘蛛抓取的行为:跳转、识别分 辨率。
首先过滤所有HTML标签、CSS样式表、JS代码
蜘蛛模拟工具:http://tool.chinaz.com/Tools/Robot.aspx
蜘蛛模拟工具:http://robot.gongju.com/
第三步:识别文字内容
通过对过滤后文字内容的分析,来判断网页的核心内容。如图所示:

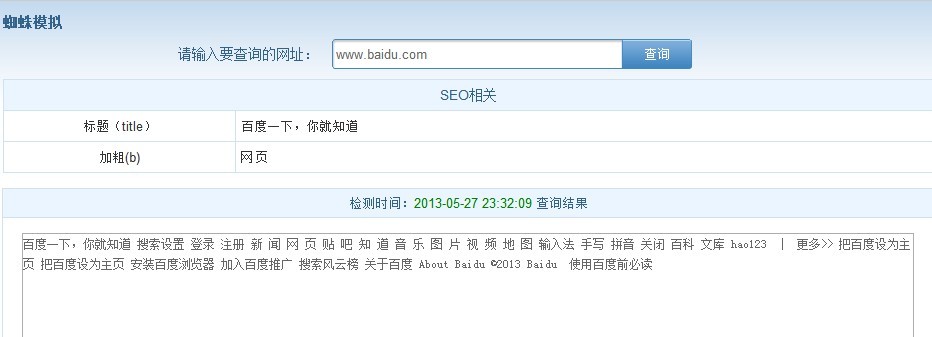
百度一下,你就知道 搜索设置 登录 注册 新 闻 网 页 贴 吧 知 道 音 乐 图 片 视 频 地 图 输入法 手写 拼音 关闭 百科 文库 hao123 | 更多>> 把百度设为主页 把百度设为主页 安装百度浏览器 加入百度推广 搜索风云榜 关于百度 About Baidu ©2013 Baidu 使用百度前必读
判断结论:本页面和关键词“百度”有密切关系。
第四步:进行权重分值技术
假设关键词重复1次得1分,那百度首页的得分就是“4” 当然,搜索引擎的真实计算过程非常负责,有数百个参数参与计算。 “所有搜索引擎最核心的是外部链接的 技术和关键词密度的技术”。
第五步:存入排名数据库
通过以上各种分析后,一个页面就可以存入排名数据库了(也叫索引数据库)。 百度首页就可能放入一个叫“百度”的小数据库中。 以后当用户搜索“百度”时,就打开“百度”小数据库,
然后按分值排列,做成HTML展示到用户面前。

一个页面上出现的关键字次数不一定等于蜘蛛抓取的关键字次数。